이미지가 안보이는 경우도 있는 것 같습니다.
이미지가 안 보이시는 분은 원본글( http://cafe.naver.com/saphana/138 ) 을 참조하시기 바랍니다.
------------------------------------------------------------------------------------------------------------------------------------
Sap hana 를 접할때 가장 많이 언급되는 것 중의 하나가 Column-Oriented DBMS 라는 것입니다
기존의 row store 방식에 비하여 column store 방식이라서 좋다는데 어떤 원리에 의하여 좋은지 이해하기 힘들었던
부분이 있어서 그 부분에 대한 설명을 적어보겠습니다.
아래 그림에서 기존 rdbms 의 row store table 과 sap hana 와 같은 column store 테이블의 특징을 볼 수 있습니다.
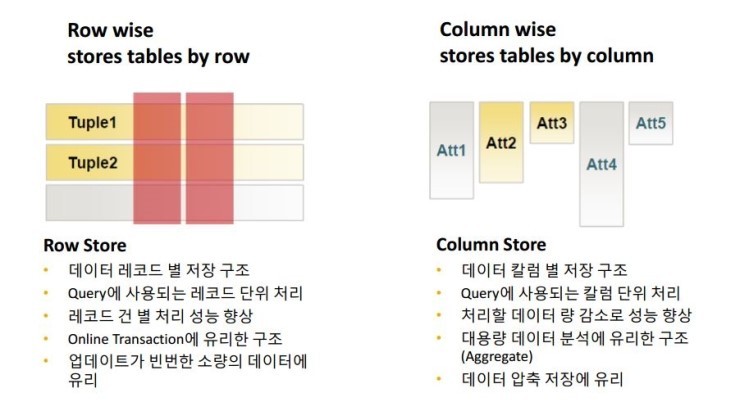
row store table 은 row 단위로 연결이 되어있고 column store 테이블은 column 단위로 연결이 되어있습니다.
아래 그림과 같이 데이타가 insert 될때 row store 방식은 row 에 데이터가 붙여지고 column store 방식은 column 에
붙여지게 됩니다
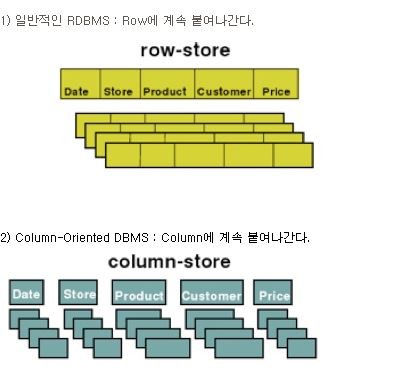
데이터에 저장될때는 아래 그림과 같이 row store 방식은 한 row 가 다 쓰여진 다음에 다음 row 가 쓰여지고 column store 방식은 한 column 의 데이터가 모두 쓰여진 다음에 다음 column의 데이터가 쓰여지게 됩니다
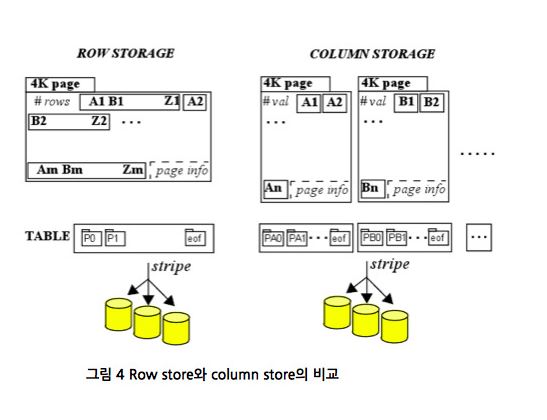
이에 더해서 sap hana 에서는 아래와 같은 데이터 압축 저장 구조를 사용합니다
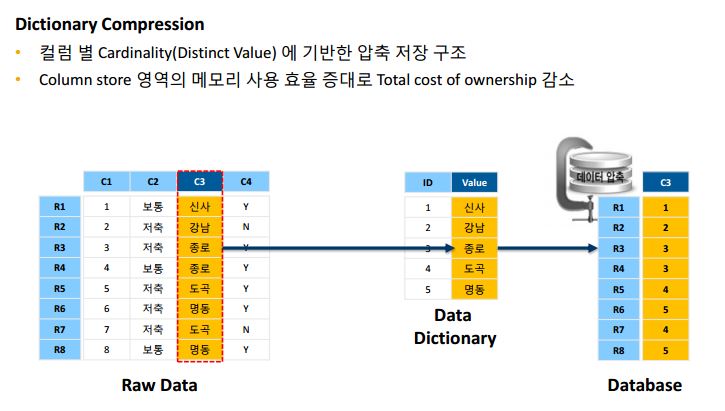
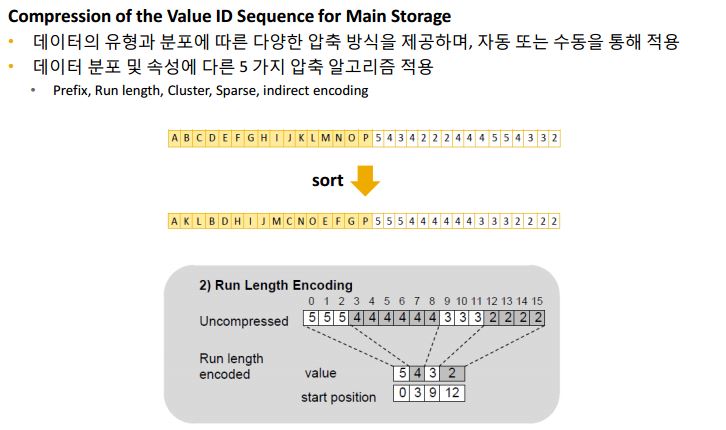
예를 들어 row store 방식의 TBL 이라는 테이블의 A,B,C,D 라는 컬럼이 1~10row 가 1page 11~20row 가 2 page 이런식으로 10 page 에 저장이 되었을 경우 column store 방식에서는 A 컬럼 1page B컬럼 2 page 이런식으로 저장이 되고 distinct value 값이 저장되어서 10page 보다 적은 공간에 저장이 될 것입니다
그리고 해당 테이블의 A 컬럼의 sum 값을 구할 경우 row store 방식은 10page 를 모두 search 해야 하지만 column store 방식은 1page 만 search 해도 되어서 row store 방식에 비하여 빠른 결과를 나타낼 수 있습니다.
(이렇기 때문에 sql 에서 * 를 사용하기 보다는 실제 사용되는 컬럼만 명시해주는 것이 좋습니다)
이에 더하여 아래 그림과 같이 멀티코어 프로세서를 이용해서 병렬처리를 쉽게 합니다
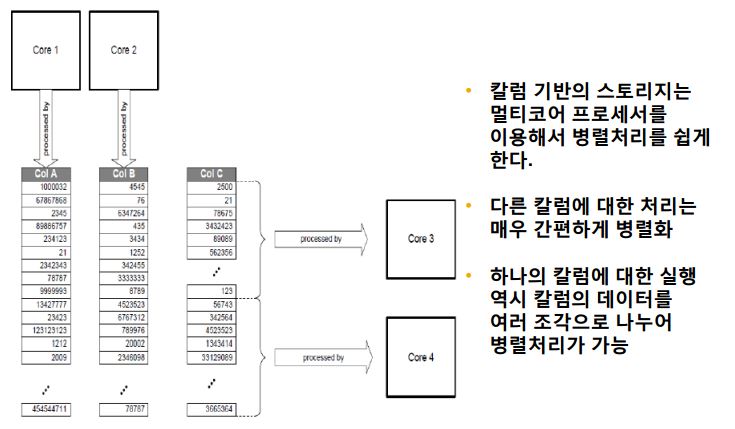
오라클에서도 parallel 옵션을 주어서 병렬처리가 가능하지만 위의 column C 처럼 row 단위로만 병렬처리가 되어서 컬럼
단위로도 병렬처리가 되는 column store 방식에 비하여 한계가 있습니다
하지만 위와 같은 방식으로 되어 있을 경우 select 속도는 빠르지만 insert , update , delete 할때는 row store 방식보다
속도가 느려지게 됩니다.
1건의 insert 가 발생할 경우 row store 방식은 1page 에만 데이터를 쓰면 되지만 column store 방식에서는 컬럼별로 나뉘어져
있는 각각의 page 에 데이터를 써야 하기때문이고 그래서 대부분의 column oriented dbms 의 경우 트랜잭션이 빈번하게 발생하
는 운영계 시스템에는 적합하지 않고 대용량 데이타베이스인 DW 나 BI 쪽에 적합하게 되어있습니다
SAP HANA 에서는 아래와 같은 delta merge 기능으로 위와 같은 단점을 보완하고 있습니다
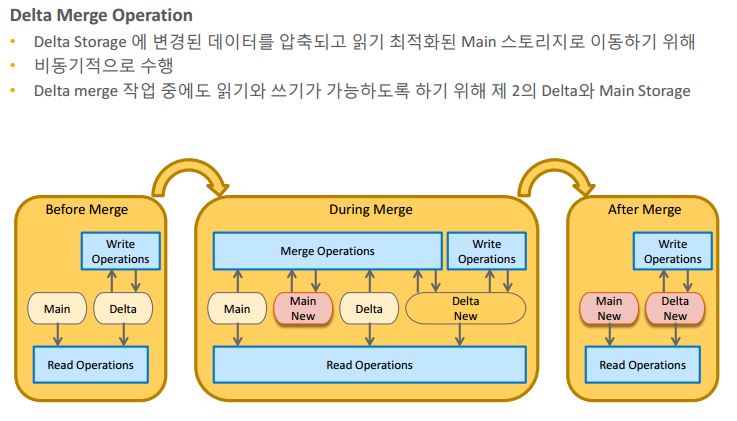
main 스토리지 와 delta 스토리지가 따로 있어서 데이터가 변경이 있을 시 delta 스토리지에 쓰여지고 main 스토리지는 그대로 있는 상태에서 데이터를 읽을때는 두개의 스토리지를 동시에 읽게 됩니다.
그리고 merge 작업을 통하여 데이터가 변경이 되는 방식이어서 트랜잭션은 빈번하게 발생하였지만 main 스토리지는 merge 할때만 데이터 변경이 일어나서 시스템 부하를 줄일 수 있습니다
처음 접하시는 분들이 column oriented dbms 에 대하여 이해하기 힘든 부분이 있을 것 같아서 정리를 해보았습니다
출처 : sap hana community(http://cafe.naver.com/saphana)
댓글 2
-
프링글스
2014.04.18 19:55
-
프링글스
2014.04.18 20:08
위의 내용을 간단하게 설명드리면
첫번째는 인터널 테이블을 사용하여 loop 를 돌리는 방식으로 하게 되면 데이타를 어플리케이션으로 전송하는 시간 + loop를 도는 횟수 만큼의
db access 가 발생하기 때문에 많은 시간과 리소스 사용을 하게 되는데 이것을 db 레벨에서 조인으로 하게 되면
한번의 db access 만 발생하고 result set만 어플리케이션으로 전송하기 때문에 전송하는 데이타량도 훨씬 줄어들게 되어서 기존보다 빠른 성능을
나타낼 수 있습니다.
인덱스는 컬럼 스토어 기반에서는 컬럼이 이미 sort 된 상태로 있기 때문에 인덱스 테이블을 타는 것은 불필요하게 중간에 인덱스 테이블을
거치면서 성능이 더 저하될 수도 있습니다.(where 구문에 조건이 많이 들어가 있을 경우 더 빨라지는 경우도 있다고 하는데 아직까지 경험해
보지는 못했고 실제로는 인덱스 테이블을 만들어도 인덱스 테이블을 타는 경우가 거의 없습니다.)
| 번호 | 제목 | 글쓴이 | 날짜 | 조회 수 |
|---|---|---|---|---|
| 9 | SAP HANA와 오라클 엑사데이터 비교 [3] | 프링글스 | 2014.07.14 | 5435 |
| 8 |
suite on hana 한글 소개 자료
[6] | 프링글스 | 2014.06.12 | 4837 |
| 7 | sap hana d-code 행사 후기 [4] | 프링글스 | 2014.05.23 | 3272 |
| 6 | abap 7.4 open sql 변경 사항 [7] | 프링글스 | 2014.04.30 | 9689 |
| 5 |
SAP HANA 기반 클라우드 서비스(MCaas)
[4] | 오른손과왼손 | 2014.04.21 | 2936 |
| » | column oriented dbms 에 대한 이해 [2] | 프링글스 | 2014.04.18 | 4578 |
| 3 | suite on hana 에서 변경되는 사항 [4] | 프링글스 | 2014.04.16 | 5383 |
| 2 | HANA Trial-30일버젼 | sapjoy | 2013.09.16 | 10489 |
| 1 | sap hana 동향 [22] | 프링글스 | 2013.09.10 | 8090 |

rune 님이 댓글을 달아주셨는데 글을 수정하다가 삭제되서 죄송합니다. 내용은 아래와 같습니다.
---------------------------------------------------------------------------------------------------------------------------------------
column store라고 하니 기억나는게 HANA를 쓰면 기존 dbms와 사용방법에서 select 할때 join을 사용하라고 하더군요. (권장이라고 하더군요) 인메모리로 하는거라서 가져와서 internal table로 하지말고 select시 가공해서 가져오는게 빠르다고 합니다. 어플리케이션 레벨이 아닌 db레벨에서 처리하라고 '권장'합니다. 그리고 table을 만들때 인덱스가 필요없다고도 하더군요. row store 가 아니라 column store라서 인덱스가 의미가 없다고 만들지 말라고 합니다. 만들면 느려진다고.. 기억나는건 이거정도네요.